NOTE: The Growth Economics Blog has moved sites. Click here to find this post at the new site.
Robert Gordon has a recent set of papers (2012, 2014) claiming that the growth rate of GDP per capita in the U.S. is going to slow down from roughly 2% per year to 0.9% per year, starting in 2007. The argument is based on a combination of factors including: an aging population, a slowdown in educational attainment, and debt levels. There are possible counter-arguments to be made on each of his individual points, but that’s not really what I’m interested in here. What I’d like to know is this: when will I know if Robert Gordon is right?
How do I figure this out? I need to get a little wonky about statistical testing. The null hypothesis I am testing is that the growth rate is 2% per year. But I don’t want to do a typical kind of statistical test. The question I want to ask is this: how long will it be before I have enough evidence to reject this hypothesis? I need to do a power calculation.
IF the null hypothesis is true, then log GDP per capita evolves over time according to

where  is some noise term that captures the fact that GDP per capita will not necessarily be exactly on the trend line. For the time series fans out there, I’m completely ignoring any kind of auto-correlation here. Why? Because I did not consume enough Diet Coke this morning to re-learn time series econometrics.
is some noise term that captures the fact that GDP per capita will not necessarily be exactly on the trend line. For the time series fans out there, I’m completely ignoring any kind of auto-correlation here. Why? Because I did not consume enough Diet Coke this morning to re-learn time series econometrics.
IF Robert Gordon is right, then log GDP per capita evolves over time according to

As  goes up and up into the future in Gordon’s world, log GDP per capita will fall farther and farther behind the 2% per year trend that I am using as the null hypothesis. Evenutally, it will fall so far behind that I will have to reject the null.
goes up and up into the future in Gordon’s world, log GDP per capita will fall farther and farther behind the 2% per year trend that I am using as the null hypothesis. Evenutally, it will fall so far behind that I will have to reject the null.
When will this happen? That depends on how quickly I am willing to reject the null. If I have an itchy trigger finger, then the first time that I see GDP per capita below the 2% trend line, I’ll dismiss the 2% null hypothesis. But this is probably too hasty; remember the term. Even if growth is really 2% per year, there will be years where GDP per capita falls below the 2% trend line. A recession, perhaps. So I don’t want to reject the null too easily.
I’ll assume a standard cut-off value for rejecting the null, 5%. If, statistically, there was only a 5% chance of observing the GDP per capita level that I did even though the 2% null is true, then I’ll reject the null. Basically, if I see a value for GDP that is a huge outlier given a 2% growth assumption, then I’ll reject that growth is equal to 2% per year. Note the the 5% is the chance that I reject the null even though it is true – it’s my willingness to accept Type I error.
Now, I can look at the data on GDP per capita over time in the U.S., and get some idea of what these cut-off levels of GDP per capita are.
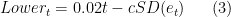
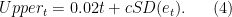
The  is the one I’m really worried about here. This lower bound is basically what I’d expect GDP per capita to be at trend (
is the one I’m really worried about here. This lower bound is basically what I’d expect GDP per capita to be at trend (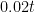 ) minus some adjustment for the possibility of a negative shock from . How big is this adjustment? That depends on
) minus some adjustment for the possibility of a negative shock from . How big is this adjustment? That depends on  , a critical value that it tied to the 5% probability of Type I error. The
, a critical value that it tied to the 5% probability of Type I error. The  tells me how variable the error term is; if shocks are really large, then it will be harder to reject the null when we see a low value of GDP per capita. The value of is roughly 2 (1.96, actually), and from the data on GDP per capita the
tells me how variable the error term is; if shocks are really large, then it will be harder to reject the null when we see a low value of GDP per capita. The value of is roughly 2 (1.96, actually), and from the data on GDP per capita the  . If you multiply these two together, this tells us that GDP per capita tends to be within +/-6.4% of trend.
. If you multiply these two together, this tells us that GDP per capita tends to be within +/-6.4% of trend.
Ok, to answer my question, I need to figure out the probability that GDP per capita given Gordon’s assumption about growth falls below this lower limit:

This is basically a power calculation. For any given year, I can calculate the probability that I’d reject the null (because  ) given that the null is false (and Gordon is right).
) given that the null is false (and Gordon is right).
Using Gordon’s assumption from above, I therefore want
![\displaystyle P[0.009t + e_t < 0.02t - c SD(e_t) ] \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++P%5B0.009t+%2B+e_t+%3C+0.02t+-+c+SD%28e_t%29+%5D+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
or
![\displaystyle P[e_t < (0.02 - .009)t - c SD(e_t)]. \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++P%5Be_t+%3C+%280.02+-+.009%29t+-+c+SD%28e_t%29%5D.+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0&c=20201002)
Given that I know something about the distribution of the terms, this probability is something I can figure out. As I mentioned above, the . The mean of is just zero, by construction. Finally, I’ll assume that is Normally distributed (probably not right, but see the Diet Coke comment from above). The value of  , given my choice of a 5% chance of Type I error.
, given my choice of a 5% chance of Type I error.
For any given year I can back out this probability from a Normal distribution, using Stata (or Excel, or the appendix of your old stats book). So what do I get? Here are probabilities that I will reject the null of 2% growth for some selected years:
- 2009: 4.9%
- 2010: 9.5%
- 2014: 52.5%
- 2018: 92.5%
You can see that early on, there was almost no way that I’d see data allowing me to reject the null of 2% growth. It’s only this year, 2014, that I even have a 50/50 shot of observing GDP per capita low enough to reject the null. But in just another 4 years, I’ve got a 93% chance of rejecting the null if it is actually false.
Be very careful here. These are not probabilities that Gordon is right. These are probabilities that I will be able to detect IF Gordon is right. So I have a 50/50 shot this year of getting a low enough GDP per capita number that it behooves me to reject the 2% growth rate. If GDP per capita is not low enough this year to reject 2% growth, then that just means I need to wait another year before I can test the hypothesis. By 2018, though, I have a 92.5% chance of getting enough information to reject 2% growth if 2% growth is actually wrong. By then, IF Gordon is correct, low growth rates will have made it almost statistically impossible to hold onto the 2% growth rate hypothesis.
These calculations are sensitive to how big a difference in growth rates I’m looking at. 2% versus 0.9% is pretty big. And 2% is roughly the average growth rate of GDP per capita since 1950 to 2007. But growth in GDP per capita has been lower than 2% that for about 2 decades now. From 1990 to 2007, the average growth rate is only about 1.6% per year. If I instead use a null of 1.6%, then it’s going to take me longer to get enough data to possibly reject that null.
Using the null of 1.6% growth (but leaving all else the same), here are the probabilities:
- 2009: 3.7%
- 2010: 5.9%
- 2014: 24.6%
- 2018: 57.4%
- 2023: 90.0%
Now, it’s not until 2023 that I will be fairly sure to have enough data to detect if 1.6% growth is wrong, or another 10 years. Prior to that, it’s unlikely that we’ll experience such a low GDP per capita number that it would compel me to reject the 1.6% growth null hypothesis.
So IF 2% growth is wrong, then in another 4-ish years I should be able to tell. By 2018, I’ll either see GDP per capita levels definitively below what I’d expect given 2% growth, or I won’t. If I do see them that definitively low, then it’ll be time to reject the hypothesis of 2% growth. If I don’t see GDP per capita that low, this doesn’t mean that 2% growth is right. It just means that I cannot reject 2% growth. Until then, I don’t know.
If I reject 2% growth in 2018, then is Gordon right that growth is 0.9% per year? Kind of. He’ll be right that 2% is wrong. But it won’t be until about 2023 that I can reject 1.6% growth. And 2043 before I can reject 1.2% growth. And well after 2100 before I can reject 1.0% growth. So I really won’t be able to tell if Gordon is right about 0.9% growth until next century.
Claims that growth in GDP per capita is less than 2% per year should be relatively easy to validate in the next decade. But finding enough evidence to nail down that growth has fallen to 0.9% is actually going to take a long, long time. So the answer to my question is that it depends on what I mean by “Gordon is right”. Very soon we can establish whether he is right about growth being less than 2%. But it’ll take a century to know if he is right about the 0.9% growth rate.
Maybe the biggest lesson here is that statistics is annoying.









![\displaystyle u'(xR) = v'[(1-x)R], \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++u%27%28xR%29+%3D+v%27%5B%281-x%29R%5D%2C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
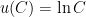
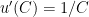


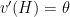



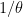
 , where
, where  is productivity and
is productivity and  is labor. The firm has some market power, and the inverse demand curve is
is labor. The firm has some market power, and the inverse demand curve is  , which says that if the firm produces more
, which says that if the firm produces more  , the price it can charge for that output must fall.
, the price it can charge for that output must fall.  is a measure of how much market power the firm has. If
is a measure of how much market power the firm has. If  , the
, the  , and the firm is a price-taker. As
, and the firm is a price-taker. As  .
.
 . This extra term
. This extra term  is often called a wedge. It’s like a subsidy (if
is often called a wedge. It’s like a subsidy (if  ) or tax (if
) or tax (if  ) facing the firm, although in most applications the wedge is not specifically associated with any tax or subsidy. It just is a stand-in for any kind of additional markup (or markdown) a firm can charge for its product. If I maximize profits for this firm, and solve for their choice of labor to use, I get
) facing the firm, although in most applications the wedge is not specifically associated with any tax or subsidy. It just is a stand-in for any kind of additional markup (or markdown) a firm can charge for its product. If I maximize profits for this firm, and solve for their choice of labor to use, I get
 . The wedge is acting like a shift up in the demand curve, and so the firm produces more, which requires it to hire more workers. If the wedge is negative, then this is like a shift down in the demand curve, and the firm will be smaller. The wedge means that firms can be large even if they are not productive, or small even if they are productive.
. The wedge is acting like a shift up in the demand curve, and so the firm produces more, which requires it to hire more workers. If the wedge is negative, then this is like a shift down in the demand curve, and the firm will be smaller. The wedge means that firms can be large even if they are not productive, or small even if they are productive. for each firm. Once you know that, roll up the output produced across all firms to find out aggregate production without the wedges. Compare this to the observed output level (i.e. with wedges). This tells you how much higher output could be if these wedges didn’t exist. This is the potential “between” productivity growth in a country. And this potential between productivity growth is intriguing, because it doesn’t necessarily mean I have to adopt a new technology or acquire new capital or workers, I just need to reshuffle the capital and workers I have to more efficient firms.
for each firm. Once you know that, roll up the output produced across all firms to find out aggregate production without the wedges. Compare this to the observed output level (i.e. with wedges). This tells you how much higher output could be if these wedges didn’t exist. This is the potential “between” productivity growth in a country. And this potential between productivity growth is intriguing, because it doesn’t necessarily mean I have to adopt a new technology or acquire new capital or workers, I just need to reshuffle the capital and workers I have to more efficient firms.
 , the capital/output ratio is
, the capital/output ratio is  , where
, where  is population growth,
is population growth,  is depreciation, and
is depreciation, and  is the growth of output per worker. You can see that as
is the growth of output per worker. You can see that as  ratio rises.
ratio rises. and typically assumed to be
and typically assumed to be  . Over time, the share of output going to capital is constant at this value of
. Over time, the share of output going to capital is constant at this value of  , where
, where  . As the capital/labor ratio rises, so does output per worker. This continues without end, because there are no longer decreasing returns to capital per worker. Even if technology is stagnant (
. As the capital/labor ratio rises, so does output per worker. This continues without end, because there are no longer decreasing returns to capital per worker. Even if technology is stagnant (