NOTE: The Growth Economics Blog has moved sites. Click here to find this post at the new site.
One of the big advantages of having written this blog for a while is that I can start recycling old material. I’m going to do that in response to the small back-and-forth that Noah Smith (also here) and John Cochrane had regarding Jeb! Bush’s suggestion/idea/hope to push the growth of GDP up to 4% per year. Cochrane asked “why not?”, and offered several proposals for structural reforms (e.g. reforming occupational licensing) that could contribute to growth. Smith was skeptical, mainly of the precise 4% value. Why 4? Why not 5? Why not 3 1/3?
Oddly enough, the discussion of Jeb!’s 4% target is also a good entry point to talking about Greece, and the possibility that the various structural reforms insisted on by the Germans will manage to materially change their situation. But we’ll get to that.
First, what are the possibilities of generating 4% GDP growth in the U.S.? I’m presuming that we’re talking about whether we can boost per capita growth up to 4% per year for some relatively short time frame, because history suggests that sustained 4% growth in GDP is incredibly unlikely. From Jeb!’s perspective, I’m guessing either 4 or 8 years is the right window to look at, but let’s say we’re trying to achieve this for just 5 years.
Here’s where I’ll dig back into the archives, where I talked about the boost to growth that you can get from various structural reforms. Literally copying and pasting from that post, there are two ways to boost GDP growth. Either
- Actively raise current GDP through increased spending by some sector of the economy.
- Raise potential GDP and let transitional growth speed up.
Let’s attack the second one first, as several of Cochrane’s proposals involve raising potential GDP through structural reforms, but involve no immediate spending changes.
We can do some quick calculations of the growth effects of structural reforms by using the following equation
![\displaystyle Growth = \frac{Y_{t+1}-Y_t}{Y_t} = (1+g)\left[\lambda \frac{Y^{\ast}_t}{Y_t} + (1-\lambda)\right] - 1. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++Growth+%3D+%5Cfrac%7BY_%7Bt%2B1%7D-Y_t%7D%7BY_t%7D+%3D+%281%2Bg%29%5Cleft%5B%5Clambda+%5Cfrac%7BY%5E%7B%5Cast%7D_t%7D%7BY_t%7D+%2B+%281-%5Clambda%29%5Cright%5D+-+1.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
This says that growth in GDP has a standard component of 

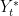
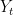

In 2015 U.S. GDP is about 16 trillion, and let’s say that right now, potential GDP is roughly 17 trillion. If that is true, then we should have growth of about
![\displaystyle Growth = (1.028)\left[.02 \frac{17}{16} + .98\right] - 1 = 0.0293 \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++Growth+%3D+%281.028%29%5Cleft%5B.02+%5Cfrac%7B17%7D%7B16%7D+%2B+.98%5Cright%5D+-+1+%3D+0.0293+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
meaning 2.93% growth.
Is it plausible to have structural reforms that will boost that 2.93% growth to 4% growth? Well, I don’t know precisely how much of boost to potential GDP we’d get from the structural reforms that Cochrane proposed and that Jeb! would apparently enact. But let’s say that it is a pretty substantial amount, like $3 trillion. This means that potential GDP in the US is now $20 trillion dollars, which is a 18% boost in potential GDP. I am granting here that these structural reforms have a massive effect on potential GDP. I am skeptical that they would actually have such a large effect.
Growth after these massive structural reforms will be
![\displaystyle Growth = (1.028)\left[.02 \frac{20}{16} + .98\right] - 1 = 0.0331 \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++Growth+%3D+%281.028%29%5Cleft%5B.02+%5Cfrac%7B20%7D%7B16%7D+%2B+.98%5Cright%5D+-+1+%3D+0.0331+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
or 3.31% growth in GDP. That’s not 4%. That’s not really close to 4%. (In one of those wonderful unintentionally funny coincidences, though, it is almost exactly Noah’s off-the-cuff 3 1/3% growth rate.) Massive structural reforms will not push the economy to 4% growth. And after the first year of growth at 3.31%, growth will keep falling until it settles back towards 2.8% per year. So the reforms will never yield 4% growth.
But won’t the massive structural reforms lead to a wave of investment as people get all excited about the new direction that America is headed? Yes. And that is precisely what the equation captures. The convergence result here is measuring the additional growth we get as people invest more due to their perception that the return on those investments is higher due to the structural reforms. Empirically, the fact that 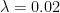
You can just scrape 4% growth is you continue to assume that structural reforms to the U.S. economy can add $3 trillion to potential GDP and that the convergence parameter is in fact 
It is this same logic that is at play in Greece, by the way. Same convergence equation, same 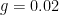
Let’s assume that the Greeks have completely taken the German structural reforms to heart. So much so that Greece simply adopts the entire German legal system, culture, and technology in one giant gulp. This doubles Greek potential GDP to 360 billion euro, which would imply that Greek GDP per capita would be roughly equal to that of Germany.
These sweeping structural reforms will generate growth of
![\displaystyle Growth = (1.02)\left[.02 \frac{360}{180} + .98\right] - 1 = 0.0404 \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++Growth+%3D+%281.02%29%5Cleft%5B.02+%5Cfrac%7B360%7D%7B180%7D+%2B+.98%5Cright%5D+-+1+%3D+0.0404+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
or 4% growth in GDP in the first year after reforms. Thereafter, growth will continue to come in below 4% as Greece converges to its new Teutonic economic bliss point.
I know very little about the Greek crisis. I know very little about the terms of the deal that Greece signed. But my limited reading tells me that this is not the kind of growth that will be sufficient for them to crawl out of the hole they find themselves in.
Massive structural reforms are not capable of generating immediate short-run jumps in growth rates in the U.S., Greece, or any other relatively developed economy. They play out over long periods of time, and the empirics we have suggest that by long periods we mean decades and decades of slightly above average growth. Ask the Germans. They’ve been fiddling around with structural labor market reforms since the 1980’s, and when exactly were they able to keep up sustained GDP growth of 5 or 6%?
The U.S. and Greece are not China in 1980 or South Korea in 1960, where you could plausibly imagine that structural reforms could boost potential GDP by a factor of 5 or 6 and generate growth rates of 8-10%. We are nibbling around the edges, by comparison.
Structural reforms don’t generate massive short-term changes in growth rates because they are fiddling with marginal decisions, making people marginally more likely to invest, or change jobs, or get an education, or start a company. By permanently changing those marginal decisions, structural reforms act like glaciers, slowly carving the economy into a new shape over long periods of time. Think of occupational licensing reform. If you enacted that tomorrow, GDP would not move at all. But over the course of the next few years, as new people graduated high school or college, or lost jobs, some of them, on the margin, would now find it worthwhile to become a physical therapist, or a hairdresser, or an interior decorator. They’d presumably be more efficient in these positions than flipping burgers, so the economy would be more efficient and GDP would be higher. But this takes years.
If you want to radically boost GDP growth now, then someone has to spend money now. Take infrastructure spending. Let’s say that miraculously Congress passed a $1 trillion dollar plan to rebuild bridges, ports, roads, and airports around the U.S. Let’s say this is going to be spent $200 billion a year for 5 years starting in 2016.
Now what is growth in 2016? GDP was going to grow naturally at about 2.93%, so we’d have about 16.5 trillion in GDP just from that. Add in 200 billion in infrastructure spending and you get 16.7 trillion in GDP. Now, what is the actual growth rate from 2015 to 2016? (16.7-16)/16 = 0.0438, or about 4.4% growth. This doesn’t even allow for the possibility that there could be a multiplier greater than 1 on the infrastructure spending.
In addition, the beauty of infrastructure spending is that is doesn’t just push us closer to potential, it almost certainly raises potential GDP as well, and keeps the growth rate above average for longer. How much? I don’t know, but I’d personally guess that it raises potential by more than 1-for-1 with the actual spending. But let’s be conservative, and assume that it simply raises potential such that the economy always stays about 1 trillion behind potential GDP. So in 2016 potential is 17.7 and actual GDP is 16.6. What is growth from 2016 to 2017? Well, it grows by about 2.93% again due to being not quite at potential, and then add in another 200 billion in infrastructure spending. That gives us 17.4 trillion in actual GDP. So actual growth from 2016 to 2017 is (17.4 – 16.7)/16.7 = 0.0419, or about 4.2% growth.
So long as we keep up the $200 billion in infrastructure spending, we can get growth of about 4% per year. Jeb!, you’re welcome. Problem solved.
The difference with infrastructure spending is that it does not nibble around the edges or play with marginal decisions. It dumps a bunch of new spending into the economy. And that is the only way to juice the growth rate appreciably in the short run. Structural reforms will raise GDP, and in the long run may raise GDP by far more than immediate infrastructure spending. But that increase in GDP will take decades, and the change in growth will be barely noticeable. You want demonstrably faster growth right now? Then be prepared to spend lots of money right now.
In the Greek situation, the implication is that without some kind of boost to spending now, they are unlikely to ever grow fast enough to ever get out of this hole they are in. If the Germans and EU are serious about keeping Greece in the eurozone and refusing to write down the debt, then they should seriously consider investing heavily and immediately in Greece. Structural reforms, even if implemented with perfection, are highly unlikely to be sufficient. The Greeks don’t have time to wait for the glaciers of structural reform to scrub the economy clean. If the Greeks aren’t allowed to do any stimulus spending, then the EU should do the stimulus spending for them. It is probably the only way that everyone gets what they want.
 , where
, where  are rival inputs and
are rival inputs and  are non-rival. If the function is constant returns then
are non-rival. If the function is constant returns then  . Take derivatives of both sides with respect to
. Take derivatives of both sides with respect to  . Evaluate at
. Evaluate at 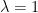 without losing anything, or
without losing anything, or  , meaning that total output equals rival factors times their marginal products. This holds, no matter what we say about how factors are paid, for a function CRS in rival inputs.
, meaning that total output equals rival factors times their marginal products. This holds, no matter what we say about how factors are paid, for a function CRS in rival inputs.  . So there is nothing left over to pay owners of non-rival inputs. The only way to pay non-rival inputs anything is to force the wage/return to be less than
. So there is nothing left over to pay owners of non-rival inputs. The only way to pay non-rival inputs anything is to force the wage/return to be less than  . Or to dismiss the assumption that the function is CRS with respect to rival inputs in the first place.
. Or to dismiss the assumption that the function is CRS with respect to rival inputs in the first place. , standing in for all the stocks of capital and people and land) and non-rival inputs (
, standing in for all the stocks of capital and people and land) and non-rival inputs ( , standing in for ideas/plans/technologies),
, standing in for ideas/plans/technologies), 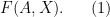
 . This in turn implies that the following must be true
. This in turn implies that the following must be true 
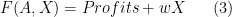
 are whatever we pay (possibly zero) to the owners of the ideas/plans/technologies.
are whatever we pay (possibly zero) to the owners of the ideas/plans/technologies.  is the “wage” paid to a rival factor
is the “wage” paid to a rival factor  . And if this is true, then the only possible way for the second expression to hold is if
. And if this is true, then the only possible way for the second expression to hold is if 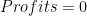 . If rival factors of production are paid their marginal products, there is nothing left over to pay out as profits.
. If rival factors of production are paid their marginal products, there is nothing left over to pay out as profits. , then you must have that
, then you must have that  , or rival factors of production are paid less than their marginal product. And the only way for this to be the equilibrium outcome is if there is not price-taking. If other firms could pay more, they would, and would equate the wage and marginal product. So positive profits imply some kind of market power (possibly a patent, or a legal monopoly, or some kind of brand identity that cannot be mimicked) for firms.
, or rival factors of production are paid less than their marginal product. And the only way for this to be the equilibrium outcome is if there is not price-taking. If other firms could pay more, they would, and would equate the wage and marginal product. So positive profits imply some kind of market power (possibly a patent, or a legal monopoly, or some kind of brand identity that cannot be mimicked) for firms.  , because there is no one to remunerate for innovating. Hence we can have price-taking by firms.
, because there is no one to remunerate for innovating. Hence we can have price-taking by firms.  is constant returns to scale over both
is constant returns to scale over both 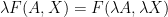 . This means that the production function is decreasing returns to scale with respect to rival inputs, and
. This means that the production function is decreasing returns to scale with respect to rival inputs, and 
 .
. 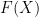 , and is constant returns to scale in the
, and is constant returns to scale in the 


