NOTE: The Growth Economics Blog has moved sites. Click here to find this post at the new site.
There has been a recent bloom of research that studies the diffusion of ideas and economic growth. Alvarez, Buera, and Lucas (2013), Lucas (2009), Lucas and Moll (2014), and Perla and Tonetti (2014) are some of the most prominent examples. In each case, firms or individuals learn new techniques after meeting other firms or individuals with better ideas. The papers show the assumptions under which this type of diffusion or imitation process will lead to constant, sustained growth.
I’ve been trying to get my head around what these models teach me about the process of economic growth. I’m going to use Perla and Tonetti (PT) as a specific example in this post, but that’s only because I need an example, and it was the last one I read.
Here’s a quick verbal summary of the model of imitation in PT:
There are a bunch of risk-neutral firms, each with an individual level of productivity. The firm can produce using its own productivity level, or it can shut down for a period and search for better productivity to imitate. If it searches, it is randomly matched with another firm that is producing, and imitates that firms productivity level for free. Searching firms compare the expected value of productivity they get from imitating to the cost of shutting down, and only low-productivity firms search and imitate. Firm productivity is Pareto-distributed. The average level of productivity is rising over time because low-productivity firms imitate high-productivity terms. Because of the specific nature of the Pareto, the distribution remains Pareto even as the average rises.
The PT model delivers sustained growth through this search and match process, while maintaining a distribution of firm-level productivities. But that isn’t due to the economics of imitation, that is due to the specific mathematical structure assumed. To see this, compare the PT model to my newly created model of growth:
There are a bunch of risk-neutral villages, each with an individual level of Tecknologie. The village can consume what it produces, or it can sacrifice all of that production as a sacrifice to the glorious Hephaestus, God of craftsmen, in the hopes that he will bestow on them insight into a new type of Tecknologie. Hephaestus is fickle, like many of the Gods, and his ways are mysterious to mortals. Hence, if the village offers the sacrifice, the new Tecknologie that Hephaestus grants them is unknown, but is equal to the Tecknologie in one of the other villages around them. Villages compare the expected level of Tecknologie from Hephaestus to the cost of sacrifice, so only low-Tecknologie villages perform sacrifices. Village Tecknologie is Pareto-distributed. The average level of Tecknologie is rising over time because low-Tecknologie villages sacrifice and are blessed by Hephaestus. Because of the specific nature of the Pareto, the distribution remains Pareto even as the average rises.
These models are mathematically identical. With a sophisticated use of search-and-replace I could rewrite PT to be a paper on the growth implications of Hephaestus worship in ancient Greece.
The point is that we can call “draw productivity from a Pareto distribution matching currently producing units (DPFAPDMCPU)” anything we want. PT call it “imitation”. In my little story I call it “blessings from Hephaestus”. You could call it “R&D”, or you could call it an “externality” or “diffusion” if you wanted. DPFAPDMCPU is just an assumption about how innovations arrive.
This isn’t to say that DPFAPDMCPU is wrong, or even a bad assumption to make. Every growth model makes some kind of unsupported assumption about how productivity arrives. Solow assumed that productivity grew exponentially, which led to constant growth in steady state. Aghion and Howitt said new innovations arrive as a Poisson process, but the productivity bump you get is always the same. In expectation, or if you have lots of sectors, you get constant growth in steady state. In a standard Romer model, the productivity bump you get from innovation is proportional to the effort you put into R&D, and growth is constant in steady state.
PT isn’t really a model of imitation and growth. It is a model of DPFAPDMCPU and growth. And DPFAPDMCPU has a clever implication, which is that the distribution of firm (or village) productivities stays Pareto forever even though we have all this churning in the distribution going on. That’s something that other assumptions about how innovations arrive can’t capture.
And PT get this distinction. This paragraph is from their conclusion:
This paper contributes an analytically tractable mechanism for analyzing growth and the evolution of the productivity distribution, with both the evolution of the productivity distribution and the technology adoption decision jointly endogenously determined in equilibrium. Thus, we can analyze the effect the productivity distribution has on adoption incentives, the effect of adoption behavior in generating the productivity distribution, and the corresponding growth implications of this feedback loop. We develop a solution technique that obtains closed-form expressions for all equilibrium objects—including the growth factor—as a function of intrinsic parameters.
Here they’ve dropped any use of the word “imitation” and talk about a generic process of “technology adoption”, which could be anything from R&D to Hephaestus-worship. PT state they have figured out how to use DPFAPDMCPU as the mathematical structure to model the arrival of new technologies to adopt, all while still ending up with a constant growth rate.
The question now is why or when DPFAPDMCPU is a better choice than other structures. In what situations, or for what types of products, or in what markets, is it reasonable to think of DPFAPDMCPU as the way that innovations arrive?
“Imitation” or “diffusion” doesn’t seem to cut it as motivation. If we take imitation seriously, then the DPFAPDMCPU structure has several issues:
- Searching firms are randomly matched with producing firms. Why random? If you’re searching for someone to imitate, then wouldn’t you search for someone with particularly high productivity? The firms are assumed to have perfect foreknowledge of the distribution of productivity, so how come they do not know which firms are the best to imitate?
- Why is matching one-to-one? If you can imitate a firm, then why can’t all of us imitate one firm? Why can’t we all imitate the best firm?
- Search costs resources, but imitation is free. That is, the searcher has to give up production to look for someone to imitate. But once they match, they can copy the productivity level for free. So productivity techniques are absolutely non-excludable. But knowing that imitation is happening, why wouldn’t high-productivity firms hold out and demand some kind of side-payment for being imitated?
In short, I’m struggling at this point to see the specific economic context for these models of diffusion/imitation that use DPFAPDMCPU or something similar. Am I missing some kind of obvious examples here? If I am, is there a reason to think that most of the innovation that occurs is due to non-excludable imitation?
Lots of models deliver a prediction of constant growth in steady state, so why are these that use the DPFAPDMCPU assumption a better description of why that happens? I think this literature would benefit from providing a clearer answer to that question.
 , where
, where  are rival inputs and
are rival inputs and  are non-rival. If the function is constant returns then
are non-rival. If the function is constant returns then  . Take derivatives of both sides with respect to
. Take derivatives of both sides with respect to  , and you get
, and you get  . Evaluate at
. Evaluate at 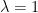 without losing anything, or
without losing anything, or  , meaning that total output equals rival factors times their marginal products. This holds, no matter what we say about how factors are paid, for a function CRS in rival inputs.
, meaning that total output equals rival factors times their marginal products. This holds, no matter what we say about how factors are paid, for a function CRS in rival inputs.  . So there is nothing left over to pay owners of non-rival inputs. The only way to pay non-rival inputs anything is to force the wage/return to be less than
. So there is nothing left over to pay owners of non-rival inputs. The only way to pay non-rival inputs anything is to force the wage/return to be less than  . Or to dismiss the assumption that the function is CRS with respect to rival inputs in the first place.
. Or to dismiss the assumption that the function is CRS with respect to rival inputs in the first place. , standing in for all the stocks of capital and people and land) and non-rival inputs (
, standing in for all the stocks of capital and people and land) and non-rival inputs ( , standing in for ideas/plans/technologies),
, standing in for ideas/plans/technologies), 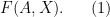
 . This in turn implies that the following must be true
. This in turn implies that the following must be true 
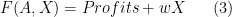
 are whatever we pay (possibly zero) to the owners of the ideas/plans/technologies.
are whatever we pay (possibly zero) to the owners of the ideas/plans/technologies.  is the “wage” paid to a rival factor
is the “wage” paid to a rival factor  . And if this is true, then the only possible way for the second expression to hold is if
. And if this is true, then the only possible way for the second expression to hold is if 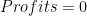 . If rival factors of production are paid their marginal products, there is nothing left over to pay out as profits.
. If rival factors of production are paid their marginal products, there is nothing left over to pay out as profits. , then you must have that
, then you must have that  , or rival factors of production are paid less than their marginal product. And the only way for this to be the equilibrium outcome is if there is not price-taking. If other firms could pay more, they would, and would equate the wage and marginal product. So positive profits imply some kind of market power (possibly a patent, or a legal monopoly, or some kind of brand identity that cannot be mimicked) for firms.
, or rival factors of production are paid less than their marginal product. And the only way for this to be the equilibrium outcome is if there is not price-taking. If other firms could pay more, they would, and would equate the wage and marginal product. So positive profits imply some kind of market power (possibly a patent, or a legal monopoly, or some kind of brand identity that cannot be mimicked) for firms.  , because there is no one to remunerate for innovating. Hence we can have price-taking by firms.
, because there is no one to remunerate for innovating. Hence we can have price-taking by firms.  is constant returns to scale over both
is constant returns to scale over both 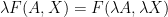 . This means that the production function is decreasing returns to scale with respect to rival inputs, and
. This means that the production function is decreasing returns to scale with respect to rival inputs, and 
 .
. 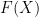 , and is constant returns to scale in the
, and is constant returns to scale in the 