NOTE: The Growth Economics Blog has moved sites. Click here to find this post at the new site.
Nearly all cross-country work on growth and development uses, if only for motivation, Penn World Table (PWT) estimates of real GDP for countries. And the PWT generates a single measure of “real GDP” for each country. How do they do this? Before I answer, let me say that much of what I’m going to say is said more thoroughly in Deaton and Heston (2010). So check that out if you’re into cross-national real GDP comparisons.
To start, let’s simplify and think just about two countries, A and B. To compare real GDP in the two countries, we’d want to value the quantities of goods they produce at some common set of prices. So say phones are $50, and haircuts are $10, and then for each country multiple the quantitify of phones times 50 and add the quantity of haircuts times 10. But what are the right prices to use? Why 50 and 10? Why not 60 and 5? You can imagine that we want the prices we use to be somewhat meaningful, and at least related to the observed prices in countries.
So here’s where it gets weird. We could say, whatever, let’s just use the prices from country B. I just need to pick one set of prices, right? But if you measure country A’s GDP using country B’s prices, then country A will look relatively rich compared to country B. This doesn’t mean it makes country A look absolutely richer than country B, just that country A now looks better in comparison. This works if you flip them around. If you measure country B’s GDP using country A’s prices, then country B will look relatively rich compared to country A. This isn’t a mathematical certainty, but reflects what actually happens if you use the prices underlying the PWT.
Let’s take the U.S. and Nigeria as an example. If we measure real GDP in both the US and Nigeria using Nigerian prices, then the US will appear to have an incredibly large lead over Nigeria in GDP per capita. If we measure real GDP in both the US and Nigeria using US prices, then the gap will appear smaller as this will make Nigeria look particularly good.
This doesn’t necessarily have to happen, it’s not some mathematical rule. But the data underlying the Penn World Tables shows that this is the case almost universally. So what is going on? It means that country A has (relatively) high prices for what country B has a lot of, and country A has (relatively) low prices for what country B has little of.
It’s easiest to see this in an example. So let the US produce  and
and 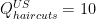 . The US produces a lot of phones relative to haircuts. And in the US,
. The US produces a lot of phones relative to haircuts. And in the US,  and
and  , or haircuts and phones cost the same. [No, this doesn’t have to be a realistic relative price for this to work]. At US prices, real GDP in the US is
, or haircuts and phones cost the same. [No, this doesn’t have to be a realistic relative price for this to work]. At US prices, real GDP in the US is

In Nigeria, we have  and
and  , or Nigeria has very few phones, but lots of haircuts. And the prices in Nigeria reflect this, with
, or Nigeria has very few phones, but lots of haircuts. And the prices in Nigeria reflect this, with 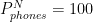 and
and  . At Nigeria’s prices, real GDP in Nigeria is
. At Nigeria’s prices, real GDP in Nigeria is

Now, those two numbers are not comparable because they use different absolute prices to value the goods. To do a fair comparison of output in the two countries, we have to use the same prices.
Let’s value Nigeria’s output using the US prices
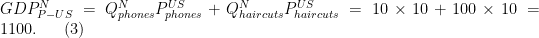
So using US prices, Nigeria looks really good. Their GDP is 1100, exactly equal to the US. They achieve this with lots of haircuts and few phones, so utility could be different in the two places, but their measured real GDP is as high as the US.
But we could equally argue that we should use Nigerian prices to value GDP in both countries. So for the US we get

The US now has GDP of 10,100, while Nigeria (at its own prices) only has a GDP of 2000. The US is roughly 5 times richer than Nigeria, when valued at Nigerian prices. Why? Because the US produces a lot of what Nigerians find expensive (phones), and little of what they don’t (haircuts).
Which comparison is right? Neither. There is nothing that says we should use the US prices or the Nigerian prices. For real GDP we simply need to pick some set of prices, and use them consistently across all countries. So much of the work in the Penn World Tables is to come up with a common price index. And the nature of this singular set of prices will matter a lot for real GDP comparisons. If the PWT uses prices that look alot like US prices, then this will make Nigeria (and other developing countries) look relatively well off compared to rich countries. But if the PWT used prices that look like Nigerian prices, then this will exaggerate the gap.
In practice, what do they do? They try to construct some kind of weighted average of the price of each good across all countries. The weights are in the PWT are calculated using what is called a Gheary-Khamis method, which essentially weights the prices from different countries by their share of total spending on that good. For phones, the weight for the U.S. is  because they produce/use 91% of all the phones. For haircuts, the weight for the U.S. is
because they produce/use 91% of all the phones. For haircuts, the weight for the U.S. is  because they produce/use about 9% of all haircuts.
because they produce/use about 9% of all haircuts.
Now in my simple example the weights are basically symmetric, because the US has most of the phones, and Nigeria has most of the haircuts. But in the real data, the US has far more phones and more haircuts than Nigeria. So in practice in the PWT, the weights are very large on U.S. prices, and very small on Nigerian prices. When they do these calculations across all countries, the weights on the US, Western Europe, and Japan dominate because they consume most of the stuff out there in the world. So the prices used by the PWT are really similar to a relatively rich Western nation [People have argued that the prices roughly correspond to Italy’s].
Which all means that every country in the PWT is getting valued at rich country prices. As we saw above, this inflates the real GDP of very poor countries, and makes them look “good” compared to rich countries. That is, the gap between the U.S. and Nigeria is much smaller using rich country (e.g. US) prices than Nigerian prices. So the PWT overall makes poor countries look very good. The true gaps in real GDP are likely larger (much larger?) than what the PWT captures.
This is not some kind of deliberate subterfuge by the PWT. “It does what it says on the tin” is a phrase that comes to mind. But that doesn’t mean it has some cosmic truth to it. The PWT isn’t doing anything wrong, but they are running up against the real fundamental problem: there is no set of prices that gives us a true measure of real living standards across countries.
What we’d like is some number that tells us that living standards in Nigeria are one-tenth, or one-twentieth, or one-fifth of those in the U.S. But what do you mean by living standards? No measure of real GDP captures actual welfare. Even if – as we’d assume was the case in a perfectly competitive market – relative prices capture relative marginal utilities, real GDP doesn’t measure welfare.
Multiplying the total quantity times the marginal utility of a good doesn’t tell me anything about the total utility that people enjoy from that good. The marginal utility of a 3rd car in my family is essentially zero, but that doesn’t mean that we get no utility from having 2. So even if there were some “right” set of prices we could use to value real GDP, it still wouldn’t measure welfare.
I think what would be useful for the PWT would be to have the full distribution of real GDP estimates for a country. That is, show me Nigeria’s real GDP valued at the prices found in every single other country in the PWT. I could plot that distribution of real GDP’s in Nigeria against the same distribution of real GDP’s for the U.S. This would at least show me something about the noise in the relative standing in real GDP for these countries. This sounds like something I can make a grad student do.
One last note about these comparisons. Recall that the result that measuring country A’s GDP in country B’s prices makes country A look relatively rich is not a certainty. It holds because there is a specific correlation of prices and quantities in the data. In each country, goods that are produced in large quantities (e.g. haircuts in Nigeria) tend to have low relative prices, and goods produced in small quantities (e.g. phones in Nigeria) tend to have high relative prices. In other words, price and quantity are negatively related. This implies that the main differences between countries are supply differences, not demand differences.
If Nigeria didn’t have a lot of phones because Nigerians didn’t like phones, then phones in Nigeria would be cheap compared to haircuts. And then valuing Nigeria’s output at the U.S. prices, which also has cheap phones compared to haircuts, wouldn’t make Nigeria look so rich. It might make them look poorer, in fact. So the empirical fact that valuing Nigeria’s output at U.S. prices makes Nigeria look relatively rich is evidence that Nigeria and the U.S. have different supply curves for phones and haircuts, not different demand curves [Yes, demand is probably different too. But relative to supply differences, these appear to be small].
. Note that here the measurement does not have to take place using only past data. We could calculate the expected measured growth rate of GDP from 2015 to 2035 as
. Measured growth rate depends on the actual path (or expected actual path) of GDP.
) and the trend growth rate of the number of workers (which we’ll call
).





 is the measure of (labor-augmenting) productivity. What exactly does
is the measure of (labor-augmenting) productivity. What exactly does  goes up, but what is that supposed to mean?
goes up, but what is that supposed to mean?  ) and labor (
) and labor ( ) are held constant?
) are held constant?

 is the real GDP number we want,
is the real GDP number we want, 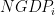 is the nominal GDP reported by a country, and
is the nominal GDP reported by a country, and 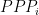 is the “purchasing-power-parity” price index for that country. While there can be severe issues with the reporting of nominal GDP, particularly from poor countries with a bare-bones (or no) national statistics office, the primary concern in these calculations is with the
is the “purchasing-power-parity” price index for that country. While there can be severe issues with the reporting of nominal GDP, particularly from poor countries with a bare-bones (or no) national statistics office, the primary concern in these calculations is with the  . So dividing nominal GDP by
. So dividing nominal GDP by 