NOTE: The Growth Economics Blog has moved sites. Click here to find this post at the new site.
I’m starting a run of several lectures on institutions in my growth and development course. By revealed preference, so to speak, I take the institutions literature seriously. But there are some issues with it, and so I’m going to teach this literature from a particularly skeptical viewpoint and see what survives. These posts are going to sound very antagonistic as I do this, which isn’t completely fair, but makes it more fun to write.
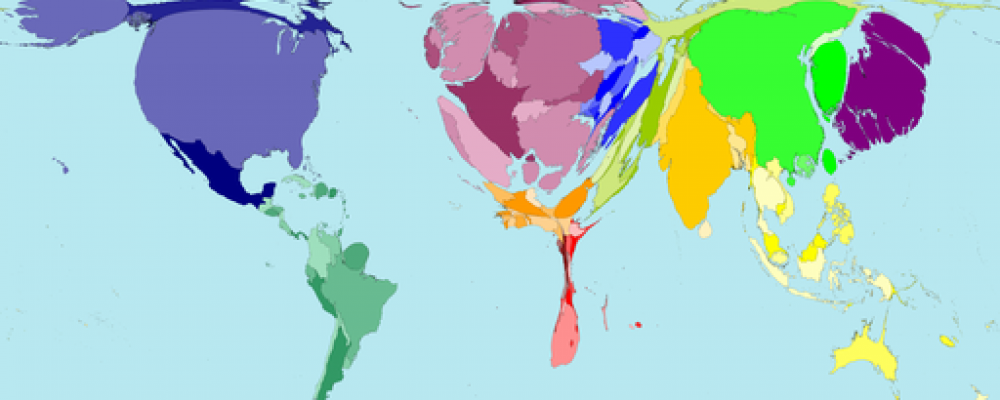
This first post has to do with the cross-country literature on institutions. The 1st-generation of this research (Mauro, 1995; Knack and Keefer, 1995; Hall and Jones, 1999; Easterly and Levine, 2003; Rodrik et al, 2004; Acemoglu and Johnson, 2005) regressed either growth rates or the level of income per capita on an index of institutional quality along with other controls. In general, this literature found that institutions “matter”. That is, the indices were statistically significant in the regressions, and the size of the coefficients indicated big effects of institutions on growth or income per capita.
These results are the prima facie evidence that institutions are a fundamental driver of differences in development levels. The significance combined with the large absolute values of the estimate effects indicated that even small changes in institutions had a big impact on GDP per capita. We’ll get to talking about questions of whether in fact these are well-identified regressions in a future post. For now, let’s just take these regressions as they are.
The first big issue with this literature is that all the indices of institutions used are inherently arbitrary, and yet are used as if they have a strict numerical interpretation. (see Hoyland, et al, 2012; Donchev and Ujhelyi, 2014) This is easiest to talk about by using an example.
Let’s take the 7 point index for “constraint on the executive” used by Acemoglu and Johnson in their 2005 paper. 1 is “not so many constraints” and 7 is “lots and lots of constraints”. There are more official definitions of these categories. They comes from the Polity IV database, and I will concede that it is coded up by smart, reasonable people. I have no argument with how each individual country is coded. Minor quibbles about how we rank constraints on executives are not going to overturn the results of the regressions using this to measure institutions.
But does Australia (7) have seven times as many constraints at Cuba (1)? Does the one-point gap between Luxembourg (7) and South Korea (6) have a similar meaning to the one-point gap between Liberia (2) and Cuba (1)? Using this as a continuous variable presumes that the index values have some actual meaning, when all they are is a means of categorizing countries.
So what happens if you use the constraint on executive scores simply as categorical (i.e. dummy) variables rather than as a continuous measure? You’ll find that all of the action comes from the category for the 7’s (Western developed countries) relative to the 1’s (Cuba, North Korea, Sudan, and others). That is, the dummy variable on the 7’s indicates that their income per capita is statistically significantly higher than income per capita for the 1’s. Country’s with 2’s, 3’s, 4’s, and 5’s are not significantly richer than 1’s (2’s, 3’s, and 4’s are actually estimated to be *poorer* than 1’s). Country’s with 6’s have marginally significant higher income than 1’s. The finding is that having Western-style social-democracy constraints on executives is what is good for income per capita, but gradations in constraints below that are essentially meaningless.
But there is a more fundamental empirical problem once we use constraints on executive to categorize countries. Regressions are dumb, and don’t care that we have a particular interpretation for our categories. They just load *any* differences in income per capita onto those categorical variables. The dummy variable for category 7 countries captures the average income per capita difference between those countries and the category 1 countries. There might be – and certainly are – a number of things that distinguish North Korea from the U.S. beyond constraints on the executive, and the dummy is picking all those up as well. Even if I control for additional factors (geographic variables, education levels, etc.. ) we cannot possibly control for everything, in part because the sample is so small that I can’t include a lot of variables without losing all degrees of freedom. Empirically, the best I can conclude is that Western-style social democracies are different from poor countries. Well, duh. One aspect of that may be constraints on executives, but we cannot know that for sure.
Other indices of institutions are just as bad. The World Bank Governance indicators, commonly used, include sub-indices of “Governance”, “Accountability”, and “Voice”. Okay, and….what do I do with that? You want to tell me Governance is good in Switzerland and bad in Uganda, I guess I’d have to agree with you, not having any specific experience to draw on. But if I ask you what exactly you mean by that, what kind of answer would I get? These governance indicators are based on surveys of perceptions of the quality of institutions. The institutions that get coded as “good” are the institutions people find in rich countries, because those must be good institutions, right? These measures are inherently endogenous.
This problem holds to some extent even for modern measures of institutional quality like the Doing Business indicators. These have the virtue of measuring something tangible – the number of days necessary to start a business, for example – but it isn’t clear that this should enter linearly to a specification. Does going from 146 to 145 days to start a business have the same effect as going from 10 to 9? Why should it? Is there a threshold we should worry about, like getting the number of days under 30? And just because we can measure the number of days to register a business, does that mean it is important, or that it constitutes an “institution”?
Reading the cross-country empirical institutions literature is the equivalent of watching studio analysis of NFL games. You have a bunch of people “in the game” of economics sitting around making un-refutable statements that sound plausible, but have essentially zero content. “He’s got a real nose for the ball”. Okay, meaning what? How does one improve ones nose for the ball? Is there a machine in the weight room for that? Is this players nose better than that players nose? How could you compare? “Good institutions” is the equivalent of “having a nose for the ball”. It’s plausibly true, but impossible to quantify, measure, or define.
Another big problem with the empirical cross-country institutions work is courtesy of Glaeser et al (2004). Their point is that our institutional measures are generally measuring outcomes, not actual institutional differences. One example is Singapore, which scores (and scored) very high on institutional measures like risk of expropriation and constraints on executives. Except under Lee Kwan Yew, there were no constraints. He was essentially a total dictator, but happened to choose policies that were favorable to business, and did not arbitrarily confiscate property. But he *could* have, so there is no actual institutional limit there. The empirical measures of institutions we have are not measuring deep institutional, but transitory policy choices.
That leaves us with the whole issue of incredibly small sample sizes, often times in the 50-70 country range, eliminating the possibility of controlling for a number of other covariates without losing all degrees of freedom. And don’t forget publication bias, which means the only things we see in the literature are the statistically significant results that got thrown up in the course of running thousands of regressions with different specifications and measures of institutions.
In short, it may be that institutions do matter fundamentally for development. But the cross-country empirical literature is not evidence of that. There is a fundamental “measurement-before-theory” issue in this field, I think. We don’t know what we should be measuring, because we don’t have any good definition of an “institution”, much less a good theory of how they work, arise, collapse, or mutate. So we end up flinging things that sound “institution-ish” into regressions, without knowing what we are actually measuring.
Next up will be 2nd-generation cross-country empirical work that uses instrumental variables. Spoiler alert: those don’t work either.


 be
be  , so that
, so that  is the price elasticity (in absolute value). As
is the price elasticity (in absolute value). As  .
. total sectors. Each one produces with a function of
total sectors. Each one produces with a function of 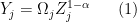
 is a given productivity term for the sector.
is a given productivity term for the sector. 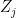 is the factor input to production in sector
is the factor input to production in sector 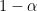 just means there are diminishing marginal returns to moving factors into sector
just means there are diminishing marginal returns to moving factors into sector  , and units of
, and units of  , the “wage”, for each unit of
, the “wage”, for each unit of  ?
?
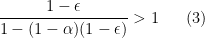
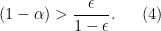
 , it pays to have concentrated productivity if the price elasticity of output in each sector is particularly low, or demand is elastic. What is going on? Elastic demand means that you are willing to substitute between sectors. So if one sector is really productive, you can just load up all your
, it pays to have concentrated productivity if the price elasticity of output in each sector is particularly low, or demand is elastic. What is going on? Elastic demand means that you are willing to substitute between sectors. So if one sector is really productive, you can just load up all your 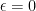 , and now we really want to have concentrated productivity. I’m better off with one sector that is hyper-productive, while letting the rest dwindle. If I could, I would invest everything in raising productivity in one single sector. So a truly open economy that traded everything would want to load all of its R&D activity into one sector, make that as productive as possible, and just export that good to import everything else it wants.
, and now we really want to have concentrated productivity. I’m better off with one sector that is hyper-productive, while letting the rest dwindle. If I could, I would invest everything in raising productivity in one single sector. So a truly open economy that traded everything would want to load all of its R&D activity into one sector, make that as productive as possible, and just export that good to import everything else it wants. 